

Software composition analysis definition
Software composition analysis (SCA) refers to obtaining insight into what open-source components and dependencies are being used in your application, and how—all in an automated fashion. This process serves the purpose of assessing the security of these components and any potential risks or licensing conflicts brought forth by them. Incorporating SCA tools in your software development workflow correctly is a significant step toward strengthening the security and integrity of the software supply chain by ensuring any borrowed code doesn’t introduce security risks or legal compliance issues into your products.
Why software composition analysis is needed
Gone are the days when software applications were built from scratch. Rampant open-source software adoption has revolutionized application development. Independent developers and enterprises can use existing components and libraries in their code to implement functionalities from simple web form validations to complex cryptographic operations.
While open-source code reuse has largely eliminated the need to reinvent the wheel, it comes with some caveats: What if the code you’re borrowing has bugs or security vulnerabilities? Moreover, what if the terms of the license carried by the open-source component conflict with your application’s license? Who is to review all this?
Review a dozen components could be a simple task to perform manually, but modern software applications are built using hundreds of libraries. These libraries may themselves have other dependencies. This process can run many layers deep, and before you know it, your application that otherwise appears to contain just a handful of libraries, may be pulling in hundreds or thousands of transitive dependencies. This is where SCA comes to the rescue.
Software composition analysis and SBOMs
Most SCA tools can generate a software bill of materials (SBOM). An SBOM is a detailed account of inventory—all dependencies and components that make up your application. An ideal SBOM provides the component’s name, version number, date of release, checksum, license information among other metadata for every component present in your application.
This can be done in one of two ways:
- Manifest scanning: The SCA tool scans your application’s build manifest files, such as package.json, for JavaScript or pom.xml for Apache Maven (Java) projects and generates a list of dependencies therein. This approach works when developers are scanning applications without the final build artifacts contained within or from a version control system (e.g., GitHub, GitLab or SVN).
- Binary scanning: The SCA tool scans your build artifacts and identifies the open-source components via binary fingerprinting. This process identifies all packages included in the final build of your application, which reduces false positives and catches third-party software and libraries added to your applicationin a non-standard way. Not every SCA tool has binary scanning capabilities.
- Manifest and binary scanning: Some SCA solutions may opt for a hybrid approach: scanning both manifests and binaries scanning to arrive at highly accurate SBOMs. Therefore, the sophistication of your SCA solution determines how precisely it can identify all components lurking in your application.
Typically, SBOMs are provided as text files in XML, JSON or similar formats that make them readable to humans and machines. Below is an example SBOM for the Keycloak application, version 10.0.2. The XML document is based on the OWASP CycloneDX standard and lists the components that make up Keycloak, including their checksums, version number, date of release, and license information. Of note is that a single version of Keycloak contains over 900 components, according to the SBOM:
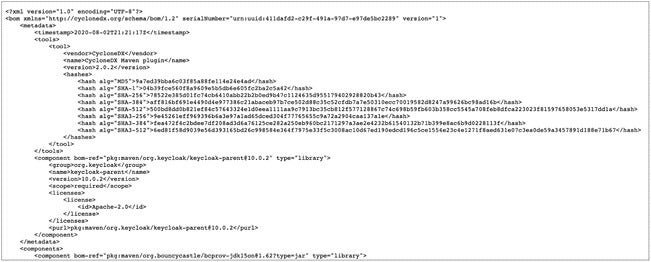 OWASP
OWASPExample CycloneDX SBOM provided in XML for Keycloak 10.0.2
Linux Foundation’s SPDX format, while still text-based, differs from CycloneDX standard. An example is shown below.
 Linux Foundation
Linux Foundation Example of an SBOM based on the Linux Foundation’s SPDX format
How do SCA tools help find open-source vulnerabilities?
Automated SCA tools can help software teams build and ship high-quality code and empower stakeholders with a proactive approach to risk management. By identifying security vulnerabilities and risks early in the software development process, SCA tools can enable software developers to select more secure components upfront seamlessly. This advantage speeds up the development process by minimizing the need for repeated security assessments as sufficient care is taken from the beginning when including third-party components and libraries in an application.
If a component with known risks and vulnerabilities is absolutely necessary, development teams can make a judgment call when the component is first introduced and contemplate adopting potential workarounds to use the component safely.
The goal of the SCA process and tools doesn’t end at merely scanning your application sources and binaries to produce an SBOM. The key challenge lies in accurately mapping each version of the component to known vulnerabilities. Further comes the compliance aspect: letting stakeholders seamlessly review and resolve any licensing conflicts posed by the components.
A few years ago, the process may have been straightforward. Simply reviewing the CVE feeds provided by MITRE or NVD and mapping them to the component versions present in your application would have been enough. Research including a paper produced by the University of Central Florida, George Mason, and Georgia Tech have shown that CVE advisories can often be inaccurate and contain inconsistencies. Other times CVE data can be misinterpreted due to how Common Platform Enumeration (CPE) data is presented in these advisories.
For example, a CVE advisory issued for vulnerability in the Tomcat server may apply to only a select component under the Apache Tomcat namespace, such as org.apache.tomcat:coyote rather than the entire Apache Tomcat namespace, but this may not be clear alone from the CPEs mentioned in the advisory.
SCA tools, therefore, need to be intelligent enough to accurately map security vulnerabilities to the impacted components as opposed to blindly trusting CVE advisories and flagging benign components. To minimize friction for developers while putting the security assessment and compliance teams at peace, SCA solutions need to minimize the occurrence of false-positive vulnerabilities in their results, but not at the risk of introducing false negatives (i.e., missing security risks). This may warrant human intervention and security research and signature-based file scanning tools.
Also, relying on CVE feeds alone for security intelligence is not enough. Vulnerability advisories may appear on product vendor websites, GitHub, and in many other places including private databases. Likewise, proof-of-concept exploits for zero-days or known vulnerabilities may appear on Exploit-DB, hacker forums, and other mysterious places. Not all SCA tools are equal and need to have sufficient capability to pull in intelligence from a plethora of sources and make sense of thousands of such inputs.
Newer supply chain threats: malware, hijacked libraries, dependency confusion
When selecting SCA tools for your organization, another challenge that arises is keeping up with novel attacks, not just known security risks and vulnerabilities.
As if staying ahead of zero-days wasn’t already a problem, we are now seeing increased incidences of typosquatting attacks and dependency confusion malware infiltrating open source registries like npm, PyPI and RubyGems, and these keep evolving.
As a senior security researcher, I have analyzed hundreds of malware samples and dependency confusion packages infiltrating the open-source ecosystem. October 2021 marked the first time we saw functional ransomware code included in a cleverly named typosquat: noblox.js-proxies. The legitimate package is named noblox.js-proxied, and is a mirror of the official Noblox.js package, a Roblox game API wrapper.
The same month, threat actors also hijacked hugely popular npm libraries, ua-parser-js, coa and rc themselves to install cryptominers and password stealers. The UA Parser library is downloaded over 7 million times a week and is used by Facebook, Microsoft, Amazon, Google, among other tech firms, demonstrating the potential impact that could have resulted from a hijack like this. Likewise, coa nets about 9 million weekly downloads and rc around 14 million.
Rather than a typosquatting or dependency hijacking attack, though, this supply chain incident involved threat actors compromising the npm account of lead maintainers behind these projects. JetBrains disclosed potential impact to Kotlin/JS developers who had run Karma test cases during the window of compromise, as ua-parser-js was one of the dependencies for the Karma testing framework.
All this gives rise to the question: Are your SCA tools capable of catching malware injections, malicious typosquats, dependency hijacks, and compromised libraries before they are distributed downstream?
Identifying the thousands of components that make up your application is in itself a daunting task for an automated tool, let alone a team of human developers. Then comes the task of sifting through the security feeds listing thousands of vulnerabilities that may or may not apply to your application. Finally, the ever-evolving threat landscape has further complicated matters for software supply chain security and integrity. Integrating a comprehensive, fast, and accurate SCA solution into your software development workflow has become indispensable but procuring one that addresses most if not all the aforementioned novel threats remains a challenge.
Copyright © 2021 IDG Communications, Inc.











{kind=link}