

Author: Tilson Galloway
API keys, passwords, and customer data are accidentally posted to GitHub every day.
Hackers use these keys to login to servers, steal personal information, and rack up absurd AWS charges.
GitHub leaks can cost a company thousands–or even millions–of dollars in damages.
Open-source intelligence gathering on GitHub has become a powerful arrow in every security researcher’s quiver: researchers from NC State even wrote an academic paper on the subject.
Hackers use these keys to login to servers, steal personal information, and rack up absurd AWS charges. GitHub leaks can cost a company thousands–or even millions–of dollars in damages. Open-source intelligence gathering on GitHub has become a powerful arrow in every security researcher’s quiver: researchers from NC State even wrote an academic paper on the subject.
This article, written for both bug bounty hunters and enterprise infosec teams, demonstrates common types of sensitive information (secrets) that users post to public GitHub repositories as well as heuristics for finding them. The techniques in this article can be applied to GitHub Gist snippets, too.
In the last year, I’ve earned nearly $10,000 from bug bounty programs on HackerOne without even visiting programs’ websites thanks to these techniques. I’ve submitted over 30 Coordinated Disclosure reports to vulnerable corporations, including eight Fortune 500 companies.
Before we get into the automated tools and bug bounty strategies, let’s talk about Code Search.
GitHub provides rich code searching that scans public GitHub repositories (some content is omitted, like forks and non-default branches). Queries can be simple like uberinternal.com or can contain multi-word strings like "Authorization: Bearer". Searches can even target specific files (filename: vim_settings.xml) or specific languages (language:SQL). Searches can also contain certain boolean qualifiers like NOT and >.
GitHub Code Search
Knowing the rules of GitHub code search enables us to craft search dorks: queries that are designed to find sensitive information.
GitHub dorks can be found online, but the best dorks are the ones that you create yourself.
GitHub provides rich code searching that scans public GitHub repositories (some content is omitted, like forks and non-default branches). Queries can be simple like uberinternal.com or can contain multi-word strings like "Authorization: Bearer". Searches can even target specific files (filename: vim_settings.xml) or specific languages (language:SQL). Searches can also contain certain boolean qualifiers like NOT and >.
Knowing the rules of GitHub code search enables us to craft search dorks: queries that are designed to find sensitive information. GitHub dorks can be found online, but the best dorks are the ones that you create yourself.
For example, filename: vim_settings.xml (try it!) targets IntelliJ settings files. Interestingly, the vim_settings.xml file contains recent copy-pasted strings encoded in Base64. I recently made $2400 from a bug bounty with this dork: SaaS API keys and customer information were exposed in vim_settings.xml.

GitHub dorks broadly find sensitive information, but what if we want to look for information about a specific company?
GitHub has millions of repositories and even more files, so we’ll need some heuristics to narrow down the search space.
By the way: with a GitHub commit search dork, we can quickly scan all 500,000 of commits that edit vim_settings.xml.
Search Heuristics for Bug Bounty Hunters
GitHub dorks broadly find sensitive information, but what if we want to look for information about a specific company? GitHub has millions of repositories and even more files, so we’ll need some heuristics to narrow down the search space.
To start finding sensitive information, identify a target.
I’ve found that the best way to start is to find domains or subdomains that identify corporate infrastructure.
Searching for company.com probably won’t provide useful results: many companies release audited open-source projects that aren’t likely to contain secrets. Less-used domains and subdomains are more interesting. This includes specific hosts like jira.company.com as well as more general second-level and lower-level domains. It’s more efficient to find a pattern than a single domain: corp.somecompany.com, somecompany.net, or companycorp.com are more likely to appear only in an employee’s configuration files.
The usual suspects for open-source intelligence and domain reconnaissance help here:
- Subbrute – Python tool for brute-forcing subdomains
- ThreatCrowd – Given a domain, find associated domains through multiple OSINT techniques
- Censys.io – Given a domain, find SSL certificates using it
GitHound can help with subdomain discovery too: add a custom regex \.company\.com and run GitHound with the --regex-file flag.
After finding a host or pattern to search, play around on GitHub search with it (I always do this before using automated tools). There are a few questions I like to ask myself here:
- How many results came up? If there are over 100 pages, I’ll likely need to find a better query to start with (GitHub limits code search results to 100 pages).
- What kind of results came up? If the results are mostly (intentionally) open-source projects and people using public APIs, then I may be able to refine the search to eliminate those.
- What happens if I change the language?
language:Shellandlanguage:SQLmay have interesting results. - Do these results reveal any other domains or hosts? Results in the first few pages will often include a reference to another domain (e.g. searching for
jira.uber.commay reveal the existence of another domain entirely, likeuberinternal.com).
I spend most of my time in this step.
It’s crucial that the search space is well-defined and accurate. Automated tools and manual searching will be faster and more accurate with the proper query.
Once I find results that seem interesting based on the criteria above, I run it through GitHoundwith --dig-files and --dig-commits to look the entire repository and its history.
GitHound also locates interesting files that simply searching won’t find, like .zip or .xlsx files.
Importantly, I also manually go through results since automated tools often miss customer information, sensitive code, and username/password combinations. Oftentimes, this will reveal more subdomains or other interesting patterns that will give me ideas for more search queries. It’s important to remember that open-source intelligence is a recursive process.
echo "uber.com" | ./git-hound --dig-files --language-file languages.txt --dig-commits
echo "uber.box.net" | ./git-hound --dig-files --dig-commits
GitHound also locates interesting files that simply searching won’t find, like .zip or .xlsx files. Importantly, I also manually go through results since automated tools often miss customer information, sensitive code, and username/password combinations. Oftentimes, this will reveal more subdomains or other interesting patterns that will give me ideas for more search queries. It’s important to remember that open-source intelligence is a recursive process.
This process almost always finds results. Leaks usually fall into one of these categories (ranked from most to least impactful):
- SaaS API keys – Companies rarely impose IP restrictions on APIs. AWS, Slack, Google, and other API keys are liquid gold. These are usually found in config files, bash history files, and scripts.
- Server/database credentials – These are usually behind a firewall, so they’re less impactful. Usually found in config files, bash history files, and scripts.
- Customer/employee information – These hide in XLSX, CSV, and XML files and range from emails all the way to billing information and employee performance reviews.
- Data science scripts – SQL queries, R scripts, and Jupyter projects can reveal sensitive information. These repos also tend to have “test data” files hanging around.
- Hostnames/metadata – The most common result. Most companies don’t consider this a vulnerability, but they can help refine future searches
Workflow for Specific API Providers
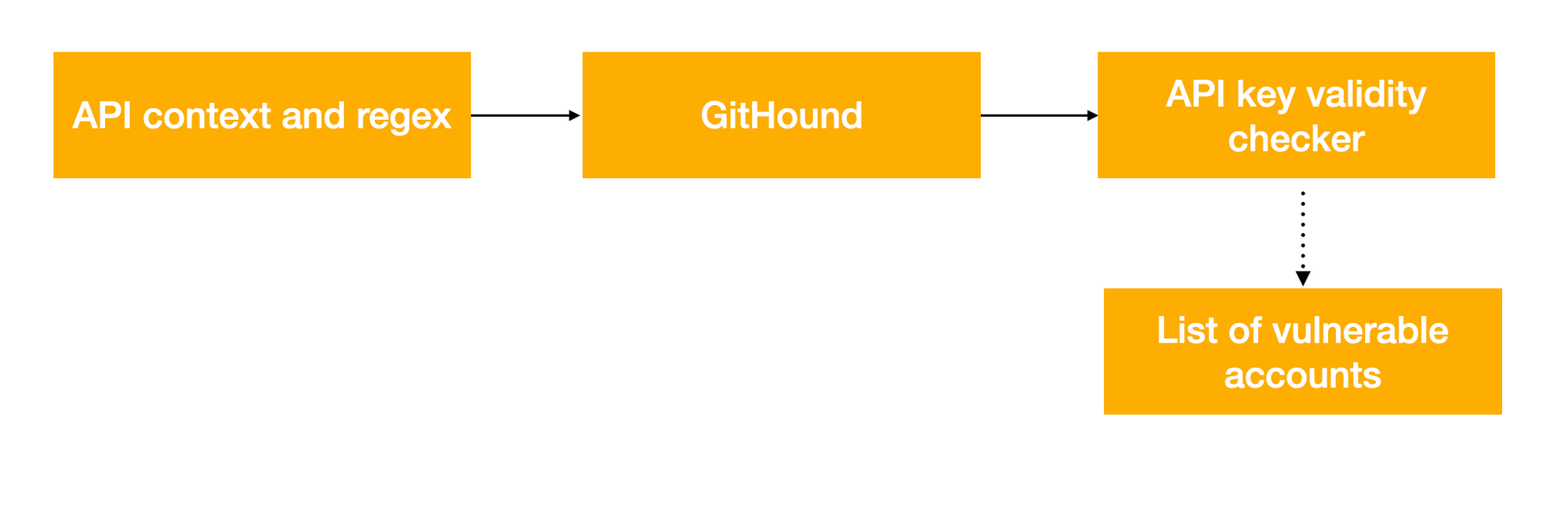
Dorks can also be created to target specific API providers and their endpoints. This is especially useful for companies creating automated checks for their users’ API keys. With knowledge of an API key’s context and syntax, the search space can be significantly reduced.
With knowledge of the specific API provider, we can obtain all of the keys that match the API provider’s regex and are in an API call context and then we can check them for validity using an internal database or an API endpoint.
For example, suppose a company (HalCorp) provides an API for users to read and write to their account. By making our own HalCorp account, we discover that API keys are in the form [a-f]{4}-[a-f]{4}-[a-f]{4}.
# Python
import halapi
api = halapi.API()
api.authenticate_by_key('REDACTED')
# REST API with curl
curl -X POST -H "HALCorp-Key: REDACTED" https://api.halcorp.biz/userinfo
Armed with this information, we can compose our own GitHub dorks for HalCorp API responses:
# Python
"authenticate_by_key" "halapi" language:python
# REST API
"HALCorp-Key"
With a tool like GitHound, we can use regex matching to find strings that match the API key’s regex and output them to a file:
echo "HALCorp-Key" | git-hound --dig-files --dig-commits --many-results --regex-file halcorp-api-keys.txt --results-only > api_tokens.txt
Now that we have a file containing potential API tokens, and we can check these against a database for validity (do not do this if you don’t have written permission from the API provider).
In the case of HalCorp, we can write a bash script that reads from stdin, checks the api.halcorp.biz/userinfo endpoint, and outputs the response.
cat api_tokens.txt | bash checktoken.bash
Remediation
Although awareness of secret exposure on GitHub has increased, more and more sensitive data are published each day.
Amazon Web Services have begun notifying users if their API keys are posted online. GitHub has added security features that scan public repositories for common keys. These solutions are merely bandaids, however. To limit secret leaks from source code, we must update API frameworks and DevOps methodologies to prevent API keys from being stored in Git/SVN repositories entirely. Software like Vault safely stores production keys and some API providers, like Google Cloud Platform, have updated their libraries to force API keys to be stored in a file by default.
Fully eradicating exposure of sensitive information is a more difficult problem: how can customer information be fully detected? What if it’s in a Word, Excel, or compiled file? More research must be conducted in this field to study the extent of the problem and its solution.











{kind=link}